
Chamber of Tech Secrets #12
Chamber of Tech Secrets #12
Developments in the Computer Vision space and why they matter
The Chamber 🏰 of Tech Secrets is open. Welcome back from the Memorial Day holiday! 🇺🇸 This week I’ll share about what I learned last week at the Embedded Vision Summit. Let’s dig in!
Why Vision?
Last week, I attended the Embedded Vision Summit in Santa Clara, CA. It was great to see some friends and observe what is developing in the embedded systems and computer vision spaces.
One of the goals I have this year is to figure out if its possible to get complete vision to a single restaurant’s operations. Can we observe cars in the drive thru, empty and occupied curbside parking spaces, customer movement in the queue and dining room, tables recently occupied for cleaning, bottlenecks in the kitchen, real-time inventory for supply chain, and more? All of these matter as they can create valuable datasets that we can use to build solutions that improve human experiences (Customers, Operators, Team Members) in restaurants.
Takeaways
Here are the key takeaways I had from my visit to the conference. I only got to attend one full day of sessions and am certain I would have departed with more takeaways if I had participated in day two.
Generative AI as a tool for training data generation: From the keynote session: “Training data is a big problem for many of us”. Generative AI becomes an interesting source of potentially high quality text, images, audio clips, videos, 3D models and so on… and at a very reasonable cost relative to historical alternatives (capturing / purchasing real images, etc.). Many of the text models have already used this approach (Stanford’s Alpaca was fine-tuned on 52k request / response records created using text-davinci-003), but generating images or video that is difficult to obtain in the real world is an interesting capability.
A lot can be performed on-chip: While much of the industry has been focused on cloud computing, training large language models with billions of parameters and huge GPUs like the Nvidia A100, or even shared edge compute footprints 🙋♂️… others have been focused on making things small. Really small. I was interested to see how many vendors in the Expo were focused on using very small (but powerful) chips to do most of the computational work related to computer vision problems on-device and only connecting out to the internet (or local network) to share insights. This was not a new idea to me, but I was surprised at its proliferation and at how small some of the devices are. The future looks to be a combination of both big and small.
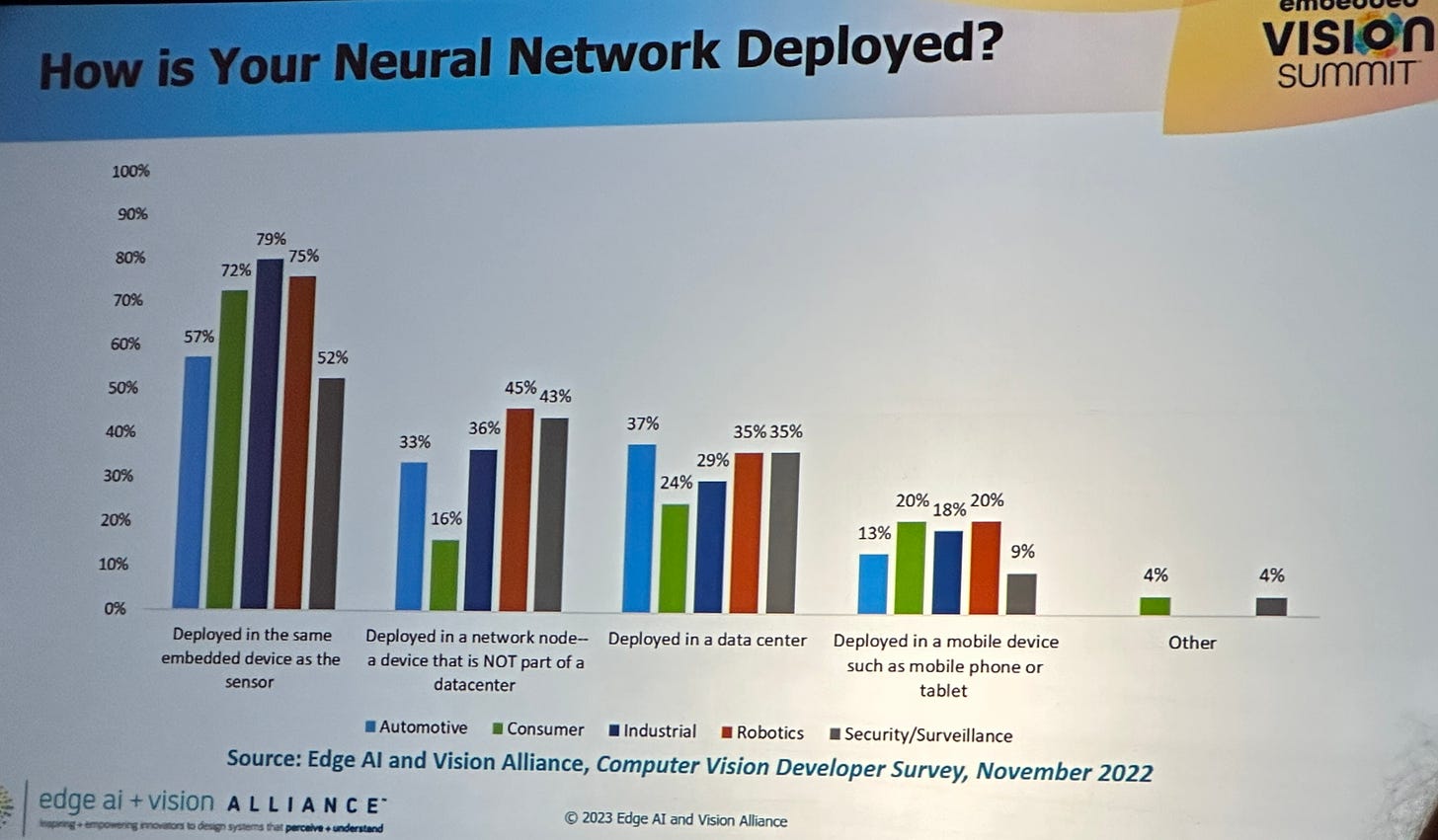
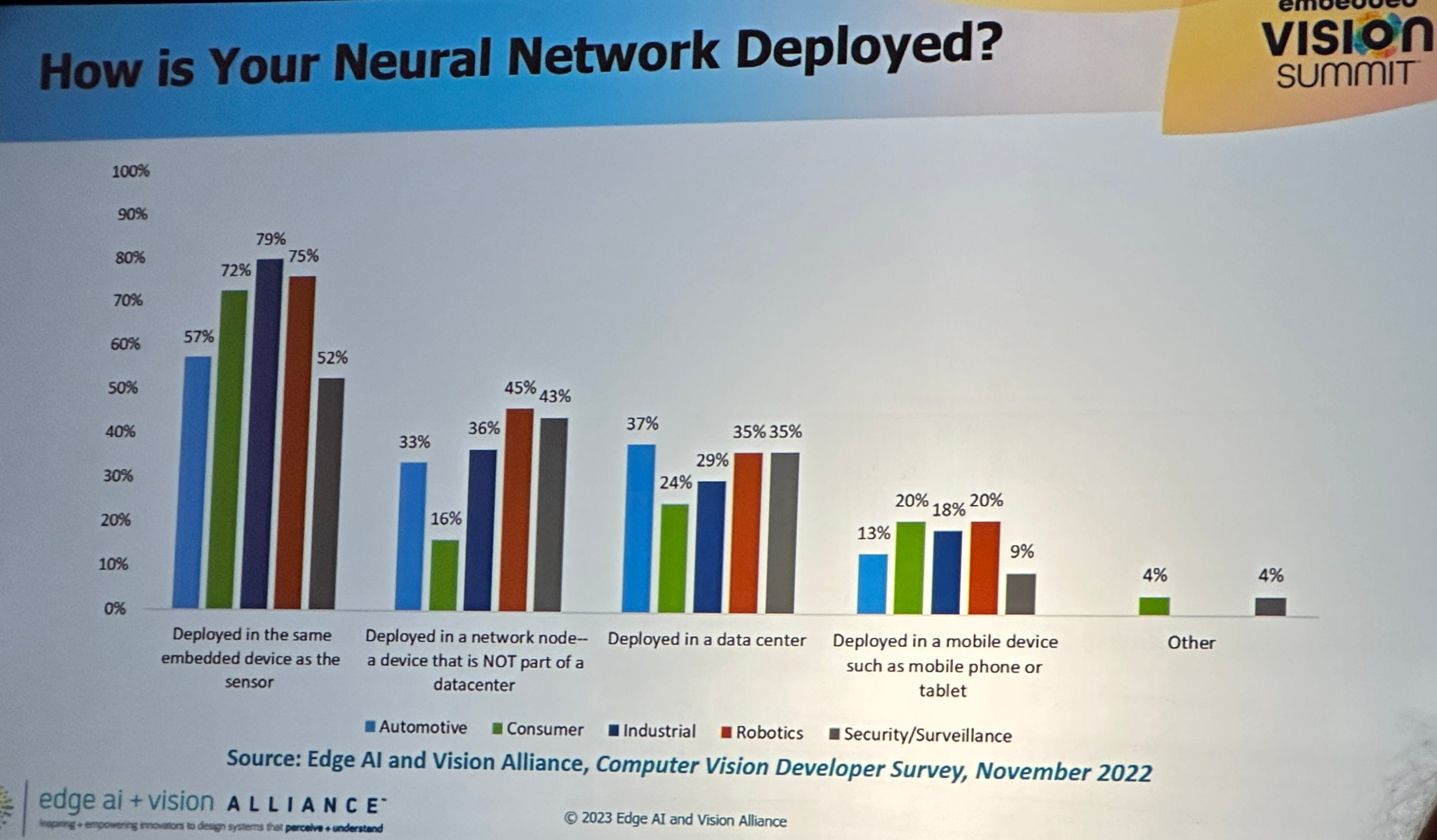
Sorry for the poor quality — taken from my phone from the audience and I did not use AI to improve it. Multi-modal sensing solutions: Multi-modal solutions are those that combine… multiple modes (Vision + Audio, Vision + Language, etc.) to solve previously challenging or intractable problems. Multi-modal was a popular theme, with many companies recognizing that a single mode is unlikely to deliver all of the outcomes they hope to achieve. Some examples of where multi-modal can help are object identity, material properties, emotion, 3d space mapping (using vision + audio - cool!), egocentric activities, ambient scenes. Kristen Grauman of Facebook AI and the University of Texas at Austin shared a lot about the developments in this space, including a cool dataset that they have been working on called Ego4D which is a ~7.1 TB dataset of vide, audio, transcription and more from human mounted sources in everyday, real-life situations.
Human-mounted vision could develop as an approach to data capture: Most computer vision solutions that I have encountered focus on mounting cameras in static locations to provide coverage, observation, and inference for objects in a static space. Shifting from third-person, static observation to first-person, human-mounted vision solutions is an interesting paradigm shift, particularly in cases where the objects of interest are difficult or impossible to observe from static locations (self-driving cars, although vehicle-mounted) and are likely to move relative to humans interacting in the environment. This got me thinking about one of our goals to achieve full visibility to everything in our Chick-fil-A restaurants, including tricky things like our inventory.
Favorite demos: A few demos in the Expo stuck out in particular.
Outsight: Lidar processing software with a lot of cool capabilities including fusing multiple lidar device feeds, establishing zones and calculating time-in-zone, tracking object movement (people, cars). They provide both turn-key, ready-to-use solutions and provide JSON feeds of the data captured should you wish to build your own solution or do something else with the data feeds. Awesome. Their solution looks really great and I am looking forward to trying it out in the near future.
Useful Sensors: Who wants sensors that aren’t useful? At the Expo, I overheard a conversation where Pete Warden (formerly of TensorFlow Mobile at Google) was talking to someone and the words “noisy environment” were mentioned. Yes, the “cocktail party” problem. I perked up since Chick-fil-A Restaurants can often be very noisy places, both in the front and back of house. Useful sensors has some cool solutions they are working on that use a multi-modal approach to [among other things] isolate the audio of a given speaker using computer vision.
Distributed management has potential to be a nightmare: With all these small devices running important workloads, one has to wonder how enterprises / government entities will operate and manage these solutions at scale. Edge Impulse and Avassa are two companies that were present for that reason (disclaimer: I have friends in leadership positions at both). I am curious to see how the management activities make winners and losers in the vision and embedded systems space in the months ahead.
Put yourself out there and make new friends: It’s not just about the technology, it’s about the people, too! I got to connect with my existing friends Spencer Huang from Edge Impulse and Carl Moberg and Amy Simonson from Avassa, which was really awesome. I also met a bunch of great new people in the Expo and at a networking event in the evening. For those who attend conferences and simply attend sessions and then retreat to the hotel room, I implore you to spend time in Expos and to attend networking events. 99% of people are cool and would love you tell you about what they are working on or have a fun conversation. Walk up and say “I don’t know a ton about this space, but what are you working on that’s cool?”. Put yourself out there and make the tech world a small world. You’re bound to have some awesome conversations and amazing experiences.

Snagging a photo with my friend Spencer. This was the first time we got to connect in person. Ship it: Jason Lavene from Keurig Dr. Pepper participated in a panel on the first day and had a brilliant statement. He said there are always going to be new things developing… data, algorithms, advanced in technology. At some point, you have to [my words] commit to what you have and use what’s available to build the best product you can until you run out of runway. Then you can pivot. I love it.

It was fascinating and fun to see a different side of the technology industry up close and to find that there were a lot of applications to things I am actively working on at Chick-fil-A.
Thanks for reading and I hope you learned something new. The Chamber of Tech Secrets is closed. If you enjoyed this post, please subscribe if you haven’t already or share it with a friend. 🙏
The Jason Lavene statement is brilliant. Love the networking advice, it can be scary but you highlight how simple and fun it can actually be.
Cool to see the tech and how it could be implemented in the wild of real life. And the limits of it, like your example of a noisy restaurant. Lab environment ~= real life. 🙏🏽