Chamber 🏰 of Tech Secrets #54: Spec-driven Development
Software development that is reliable, fun, and still vibey
Vibe Coding 🏄♂️
Can you really vibe code an application that works without writing any lines of code yourself? We seem to be in a weird place right now. Some engineers dismiss AI coding tools with a hand wave and a thought of “it can’t do what I do”. Other “engineers” are one-shotting apps into “production” with no understanding of what an HTTP header or a container is.
What a time to be alive!
Allow me to tell you about my experience vibe coding, the process I have been using, what I’ve learned, and what I plan to do in the very near future.
My Experience
I have vibe coded quite a bit over the past 4 months and have experimented with a number of tools and approaches. Tools like Cursor, Windsurf, and Claude Code. Approaches like one-shot “build me an app that does X, Y, Z… <long prompts>” or “build me a feature that does X”.
In my first attempt, I finagled my way to a working application with a simple REST API in golang (a language I’m very comfortable in) and a frontend written in React/NextJS (an entire programming paradigm I avoid whenever possible) via Cursor. Given the misguided paths along the way, that application took me about 4-5 hours over a few days to get working the way I wanted with pretty good quality.
Needless to say, I was hooked! 👏

Then, a few months ago, I came across the idea of spec-driven development which was quickly validated and expounded on by a lot of the content at the AI Engineer World’s Fair event I attended in San Francisco in early June.
My Process
There is a lot of good information available about using AI tools to write software, but I thought it would be good to consolidate my own workflow here. Here is what I do currently.
We’ll walk through the process step-by-step.
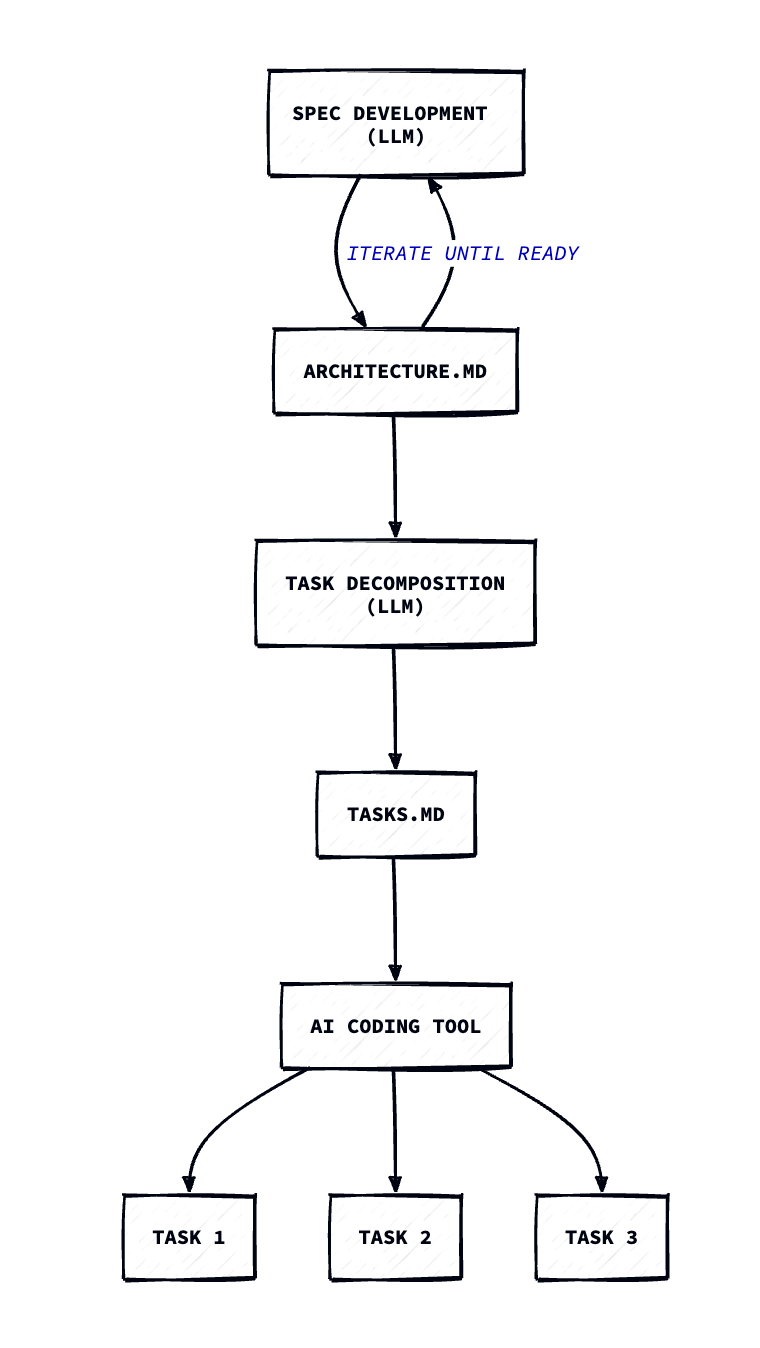
Design Loops
The first thing I do is iteratively develop a specification file named architecture.md. Ideally, this artifact lives longer than the code and enables re-generation of the code base in the future.
Practical? 🤷♂️ Useful to get a good v 1.0? ✅
Architecture Specification
Here’s how I build my specification, which is a mix of steps, tools, and thought processes co-mingled.
Tooling: I master my specification in markdown in Obsidian so that I can jump around the process in my conversation with the friendly LLM. I name this file
architecture.md.LLM help: I usually start with a prompt describing what I want to build and ask the model to generate an architecture specification in markdown. Reasoning models are great for helping with the
architecture.mdcreation process. I am pretty happy using Gemini 2.5-pro, Claude Opus 4, or OpenAI GPT 4-o or o3.Handcrafting: Having done this a few times, I have learned that sometimes it is often worth the time to put more manual work into this file. Don’t shortcut here — describe what you want. Be extremely clear about the features you want, how you want them to work, what you want the tech stack to look like (uv for python, standard go http vs gorilla mux, postgreSQL, etc.), and what “done” looks like.
Other stuff: You may want to put the DDL for databases (I usually generate that with the model iteratively) or the REST API endpoints you want to see built in the spec. You might want to put references to particular specifications (use MCP, use the Google API design specification, etc.) you want to follow. You might want to put a generated project structure in too. Honestly, more seems to be better.
Write as if for a child: “you must use MCP and follow the specification found at <link> exactly. Do not deviate from the specification under any circumstance and ensure the code implementation is compliant with the spec.” It is essential to be very specific about your expectations, much as if you were helping someone on their first programming project.
This specification development step takes about 50% of the total project time with my current process.
Here is an example of the architecture.md for a simple task management API and MCP server I put together for niche use on a personal project.

Task List
The next step is to create a list of tasks that, once completed, result in a codebase that meet my functional and technical requirements.
To do this, we take our architecture.md and leverage an LLM (I like Claude Opus 4 or Gemini 2.5-pro for this purpose) to create a comprehensive task list. Here is a prompt similar to what I use when performing this task:
Prompt: “Your job is to create a task list to complete the project that is defined in the file `architecture.md`. Each task should be small, highly testable, and designed for a large language model to complete. Ensure the foundational tasks (database setup, project setup, foundation code components like servers) are defined first so that the following tasks can leverage them. Provide the task list in markdown format.
The resulting tasks.md is usually pretty good, but I open it in Obsidian and do some adjusting to make sure I like the way everything comes out. As I read the tasks, I usually think of things I should have added in architecture.md at the start, so I will make those changes (and regenerate tasks) too.

This process usually takes about 5% of the total time on a given project (10-15 minutes tops).
We now have our two essential artifacts: architecture.md defining our solution requirements and application features and tasks.md defining the list of tasks that must be completed to
Development Loops
Now let’s talk about how development loops work, which is our implementation phase.
In this phase, we iterate through our tasks with identical (or nearly so) prompts like this one.
Please familiarize yourself with the architecture in architecture.md. Once you are ready, create a plan for executing Task 11 in tasks.md. Always write minimal code. Ensure everything developed is thoroughly tested and that all tests pass before the task is considered complete. Ensure that everything written for the MCP server is compliant with the MCP spec, per the architecture.md instructions.
Note that our architecture.md specification is going to get read on each prompt (by design) so it will be freshly injected into our context window. We’ll do the same for the specific task we’re working on.
At the end of each task—assuming we like what we see—we’ll ask the model to git add and commit because this is far too much work for us to do ourselves.
This is also a great time to ask questions about the current code base if you want to make sure that things are on track. Take a peep at the code too and make sure the structure is looking good.
From a tool perspective, my current process leverages:
Agentic Coding Tool: Obviously we’ll need an AI-assisted or driven coding tool. My favorite has quickly become Claude Code over the past month or two, driving me to the “max” subscription so I can jam away as much as I want. I was running out of tokens before, hence the switch. For those unfamiliar, Claude Code is entirely terminal based. I have my own
claude-yoloalias so I can bypass questions and permissions when needed and let it work a task from end-to-end.Visual Studio Code: I keep VSCode open so I can look at code changes here and there and make tweaks if needed (very rare).
Remember that AI Engineering is Context Engineering, so manage your context window thoughtfully. Claude Code tells you what percentage remains before auto-compaction. It is often prudent to proactively compact the context at the end of a feature, or clear it altogether so that you can run through each task and any subsequent iteration without running into the end of the context window, which always results in… well… lost context. 🤷♂️ Carry over context is not that important since everything that matters should be in the architecture.md and tasks.md files.
Maintaining the spec
Naturally, no specification is written perfectly and there inevitable misunderstandings as tasks get completed, tested, and reviewed (by me). What to do about the architecture.md? What has worked well for me is working iteratively (2-3 loops) on changes that are needed to the code, then asking the LLM to also make updates to the architecture.md file to reflect the design changes. In fact the architecture.md you saw earlier was actually co-edited by me and Claude Sonnet 4. This keeps our specification in good standing but lets us account for shortsightedness in design thinking.
Code Review Loops
Intermediate AI Code Reviews
As the development process proceeds, I like to interject a code review every 3-4 tasks to see how things are looking. Here’s what that looks like:
Prompt: You are a deeply experienced, highly critical software engineer. Please conduct a deep and thoughtful code review of the code base you find here. Only tasks 1-3 have been completed so far, so you will need to ignore other features and focus on the quality of what has been implemented. Be sure to root in the architecture.md for project goals, tech stack and guidance. You may find the tasks in tasks.md at the root of the project.
This often yields some findings which I will address iteratively. If there is anything that justifies an architecture.md update, we’ll make that change as well.
Final AI Code Review
Prompt: Please complete a final code review of this project. Be very diligent about software quality, testability, security, specification compliance, good REST practices, and minimal lines of code. Call out anything that is not well done or up to standards. Make sure all of the architecture.md features are implemented and the coding practices were followed. Provide recommendations for anything that should be improved, removed, or cleaned up. Ensure we have good logging and error handling throughout. Think long and deeply about this review.

Final Human Code Review
Finally, it is time for a thorough human review to make sure everything looks good. I typically find that Clade Code has left a few linting errors behind, so I’ll use Cursor to fix those. It is really good resolving these types of issues and it’s as simple as clicking on the code line and then “fix in chat” and hitting enter.
Lessons Learned
Be explicit: Being explicit about the behaviors you want is essential. Logging, error handling methodology, use of an LLM… If you are not clear, you’ll get something that is not what you want. Be clear about tech stack, minimal code, consistent logging and error handling, and everything else that is normally in your head when you work on a project yourself.
Active the key terms: Prompts like “minimal code” and “easily readable” and “simple as possible” seem to yield good quality results within this process. Claude models also react to “think about this”, “think
Think product, think architecture: I name the file architecture.md for a reason. I think architecture thinking will increase in importance over the next several years as mass producing code becomes so easy. Good ideas + good explanations + good understandings of how to design things + good process = good outcomes. 🚀
n tools > 1: Use the right tools for the job. My spec-driven development involves Claude Code, Obsidian, Google Gemini or ChatGPT o3, VS Code, terminals with tmux for testing, and Cursor.
Commit early, commit often: If things go sideways, this is your safety net. It’s good practice anyway.
Code Review Frequently: Prompt for code reviews every 3-4 tasks.
Update the specs: Update architecture.md and tasks.md if you discover new architecture needs, features, or tasks that should be completed. Well, have the LLM do it, of course.
Integration tests are life: Integration tests are the best way to tell if you code is really working properly so make sure to have the model write them as early as possible—preferably first—and then iterate until they pass. I do not always do this but I do ensure the tests are good and pass before moving on (usually).
Make a plan, review the plan: I usually put Claude Code in
plan modewhen giving it a task, and I do review these plans before switching back to “yolo” mode. This has allowed me to catch the model over-engineering with features like in-memory caching for a super low-volume REST API that I am running on my laptop.Yolo mode: Speaking of,
yolomode is a must unless you want to stare at the terminal and wait for a request to run acdordocker composecommand. There are obvious risks here, but they are acceptable given my current use. And I have a future plan!
My Future Plan
I have plans.
The task management API and MCP you see alongside the example
architecture.mdfrom early in this article supports this next step. Put projects and decomposed tasks here.Create an ambient agent that watches for new tasks for a given project that need to be completed.
Allow the ambient agent to farm the task to an instance of Claude Code running in a docker container in a git working-tree, powered by container-use (thanks Dagger/Solomon Hykes!). This agent will manage what tasks can be worked on in parallel vs linearly.
Have the agent working on the task submit a PR for the working tree when the task is complete.
Have a team of agents perform a code review on the submitted code. Three agents is my current thinking: 1) bias for architecture 2) bias for software engineering best practices and minimal code and 3) bias for cybersecurity. These will likely have standardized, structured prompts that can be fetched from an MCP server on-demand for consistency across projects.
Revise the code based on the feedback from the reviewers.
Assign to Brian for final human review.
Merge and trigger CI pipeline and deploy to next stage environments.
Profit.
This should let me start building solid tasks (perhaps taking more requirements away from architecture.md and keeping it more as guardrails) and then completely automate the in parallel. 🚀 Let’s go!
Will there be challenges with large or complex projects? Absolutely. Will this build you a competitor to google search? No. But for many business or personal applications, this flow can work quite well. Keep it simple and take small steps one step at a time. The models and tools are only going to get better. Happy vibing!
Are you vibe coding? Or have you moved to specification-driven development? What has your experience been? I’d love to hear from you in the comments or on LinkedIn. Until next time, keep the vibes going 🏄♂️… but don’t delete all the files on your laptop or your companies get repo. 🤪
Do you see any value in adding standard development and architecture design docs into your flow? For example … consuming a pre-existing ADR, or generating one at the end of your process?
Your architecture and tasks MD are optimized for vibe coding, but may not help six months down the road when a developer may scrub in to maintain a component or port it to some other environment.
Just thinking about how to lubricate the handoff back and forth between human and machine.
I'm going to lean into your approach. I've been on the same boat for a few months playing with Vibe coding (quasi Vibe coding) but for some reason I feel compelled to take over and code or move on to the next random project I want to play with without seeing the whole thing thru.